The GUI only has one kind of window, and that is a view on a block, which is the top level of score organization. All blocks have the same physical structure, which boils down to text in various places. How that is interpreted and becomes music is the business of the deriver. So the UI elements described here have links to a parallel structure in the derivation doc.
One important thing to know about the UI is that it is, like the rest of the program, organized in many layers. The lowest layer is the C++ API, which just opens windows, changes colors, etc. but has no idea what any of that means. This is represented mostly by the API exposed in Ui.Block.BlockC, which is a direct wrapper around the C++ API. The medium level is mostly dumb, in that you alter haskell data structures and the UI then changes to reflect the changes, but you are still free to alter them in just about any way you see fit. This level is what you see if you directly manipulate Ui.Ui.State, which you could do if you wanted, or slightly higher level if you use the functions in Ui.Ui, which is what you should probably do. The high level is defined by what Cmds are available, and it is at this level that UI changes have “meaning”. For example, a “K” in the edit box means that kbd entry is enabled only because there is a Cmd that notices when kbd entry is enabled (Cmd.Internal.sync_edit_box) and calls Ui.Ui.set_edit_box. This is all to say that most of what is described here are simply the conventions established by the default set of Cmds, and if you write your own Cmds or override the defaults you can change things arbitrarily. So you could put other letters in the edit mode box if you wrote a Cmd to do that.
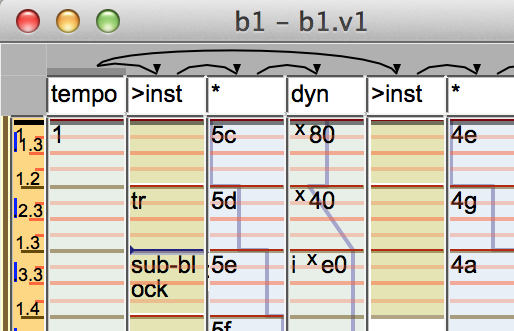
Each block is named by a BlockId, and the name part of the ID is in the window title, followed by the ViewId.
Below that, there is a text input, which is the block title. This actually hides itself when it’s empty, and you can get it to come back by double clicking on the skeleton display.
The skeleton display has arrows from track to track. The meaning is defined in the derive layer, but the short version is that it represents which tracks scope over which other tracks.
To the left of a the skeleton is a blank gray box that displays the edit mode, and below that is the ruler.
To the right of the ruler are vertical tracks, which is the bulk of the window. The tracks have events, each of which has a red line at its trigger point, a duration, and a bit of text. Some events (for instance, most events on control or pitch tracks) have a 0 duration, so they’re just a red trigger line and a bit of text. Tracks and events are color coded based on their type. This doesn’t have any semantic meaning, and is analogous to syntax highlighting. The tracks may also have any number of selections.
The bottom of the window has a status display, which displays some highly abbreviated bits of app state. The various status fields are from the “status view” section of App.Config.
There’s another tiny little gray box in the lower left corner. This shows play status: gray when ready to play, light blue when the score needs to be rederived, dark blue when derivation is in progress, and green when playing. There’s a few seconds of delay between light and dark blue so it can avoid starting a new derivation if you’re about to do another edit.
That’s all!
Text input boxes expand temporarily if their text is too large to fit. It’s not very satisfactory, but I couldn’t come up with a better way to cram text into small spaces.
In a text edit box, control-h and control-l skip backward and forward by a token, where a token is a space separated word, a symbol, or a parenthesized expression. TODO maybe it should just be a word. Holding shift extends the selection as usual. Control-backspace deletes a token. Otherwise, they use the shortcuts documented on fltk’s Fl_Input. If you play on a MIDI keyboard, it will insert pitch expressions.
Scores can look nice with specialized symbols. There are two ways to do this. One way is to just enter the symbol directly, using an IME or character palette. You should be able to bind a call to any unicode word without spaces. The disadvantages are it can be an awkward way to type, you can’t specify the font, it’s unreadable if you don’t have the right fonts installed, and it can only represent glyphs that you can directly emit via unicode.
Symbols are an alternate approach. Any text surrounded by backticks `like this` is looked up in a static symbol table, and if found, replaced with the rendered symbol. Ui.Symbol.Symbols are registered in the table at startup. They are a composition of multiple unicode glyphs, with individual fonts, size, alignment, and rotation. The name to glyph map is declared statically in the source, although it’s spread around based on who is using it: Derive.Call.Symbols, Derive.Scale.Symbols, and Derive.Instrument.Symbols. They are collected at startup time and loaded by App.LoadConfig. If the fonts don’t exist, it warns at startup, and the symbols fall back on a readable if not so pretty representation. The major disadvantage of this approach is that you have to declare every symbol explicitly in the source, and remember its name.
All this said, I’ve wound up not using symbols very often. You can still express quite a lot with ASCII and it’s easier to type. For example, I’m not yet sure whether I prefer a plain tr or a fancy trill symbol, or i o e u a vs ᭦ ᭡ ᭢ ᭣ ᭤, though in the case of sharps and flats I’ve decided on plain ASCII # and b.
Backticks also support font size and style changes. If you write `+4/xyz`, then xyz will be rendered with a relative size increase of +4. In addition to + or - a number, you can also write `bold/xyz`, `italic/xyz`, or `bold+italic/xyz`. In this case, the xyz is printed literally, it’s not the name of a symbol. This is used in the ruler labels, so it can make larger beat divisions more prominent. I don’t recommend fancy markup anywhere else.
IDs are names for the major score elements. ViewIds name Ui.Block.Views, BlockIds name Ui.Block.Blocks, RulerIds name Ui.Ruler.Rulers, and TrackIds name Ui.Track.Tracks. When you want to do something with one of those, say create a view for a block, modify a ruler, or whatever, you wind up using the ID to name it. Ultimately IDs all turn into lookups on the maps in Ui.Ui.State.
Each ID has a namespace and a name component, e.g. (bid "namespace/name") is a BlockId. Each score has a default namespace Ui.UiConfig.config_namespace. New IDs get the default namespace, and when writing a block call you normally just write the name, leaving the namespace implicit. The idea is that you should be able to merge two scores together and avoid ID clashes.
Identifier naming is more strict than most languages. Only lowercase letters a-z, digits 0-9, period and hyphen are allowed. IDs also allow `s so BlockIds can embed symbols. This enforces a lowercase-with-hyphens naming scheme. The exact definition is in Derive.Parse.p_identifier.
The intent of the restrictive rules are that they relieve me of the burden of remembering a naming scheme (e.g. ‘.’ vs. ‘-’ vs. ’_’) and leave room for flexibility in other places, e.g. @-macros in the REPL.
All the interesting things you can do with Ui.Ui.State is facilitated by cmds, so you should look at the cmd documentation.
There are several ways to define calls for a score, with different trade-offs.
Defining them in haskell and statically linking them in is the most powerful, since you have a real programming language. You also have source control, tests, a module system, and documentation. But it’s also the most heavyweight, so it’s appropriate for “library” type calls that will be used in multiple scores.
A middle ground would be to define them in haskell, and dynamically load them in to a single score. They have the full power of haskell, but since they’re not global they don’t need modules and documentation, and the score itself is the test. To do this I’d have to implement dynamic compiling and linking, which is not implemented yet. They would lack a module system, source control, and tests, so it might be a better idea to put them in Local as normal modules and link them statically. We’ll see.
A more concise way is to define the calls in tracklang. This is limited to combinations of standard calls. Small expressions can be defined inline in the score with the = call, e.g. ^down-to = "(g 2 1), but this is cumbersome if there are a lot of them.
If you set Ui.UiConfig.config_ky_file, the tracklang call definitions in the file are loaded each time it changes. Then the built-in calls can focus on being flexible if verbose, and rely on local definitions to “instantiate” them in a way that makes sense for the specific score. The syntax is described in Derive.Parse.parse_ky.